DevBlog: FBX Loader
Edict
This week my efforts have been focussed on finalising the initial functionality of our new FBX loading library, followed by the first efforts at loading multi-file FBX model data.
FBX
The FBX file format is quite common in the industry. It is a flexible way to store geometry, animation, material, and other visual data.
Most content pipelines can export and/or ingest FBX data in some way. We use FBX as an export format from Maya (and occasionally Blender), and an import format for our model processing and compilation tools.
I’ve been focussed on finishing the first pass at our animation system so that James can start seeing more of his work in engine. As part of this we identified one capability that we’d really like to see: the separation of geometry and material data from the animation data. That is to say, we would like to:
-
Apply multiple animations to one mesh. eg, 'model.fbx' stores the geometry, '[email protected]' stores the walk animation, '[email protected]' stores the run animation.
-
Apply one animation to multiple meshes. eg, 'human0.fbx' stores one human mesh, 'human1.fbx' stores a second human mesh, and '[email protected]' stores the common walk animation.
I’ve used libassimp to handle the loading of static geometry data for a few years and it’s been pretty capable overall (though the build system has caused intermittent problems with cross compilation). [1]
Unfortunately we hit a bit of a wall over December.
Of nodes and transforms
An FBX file contains — in part — a tree of named transforms I’ll refer to as 'nodes' that generally correspond to joints in a model. The animator controls the movement of nodes by defining a set of 'curves' which define their translation, rotation, and scaling over time.
Each node effects its children. eg, Moving 'R_armA_shoulder' will also move 'R_armA_elbow', which will also move 'R_arma_wrist', and so forth.
The movement of these nodes defines how the mesh will change over time. Each vertex in the mesh calculates its position by combining the transforms of some of these nodes as they move about the world. eg, the position of the upper arm will be driven by a combination of the transforms for 'R_armA_shoulder' and 'R_armA_elbow'.
We can end up with a reasonably broad and deep tree of nodes if we want to animate an object in detail. Our 'manModel' contains nearly 50 nodes.
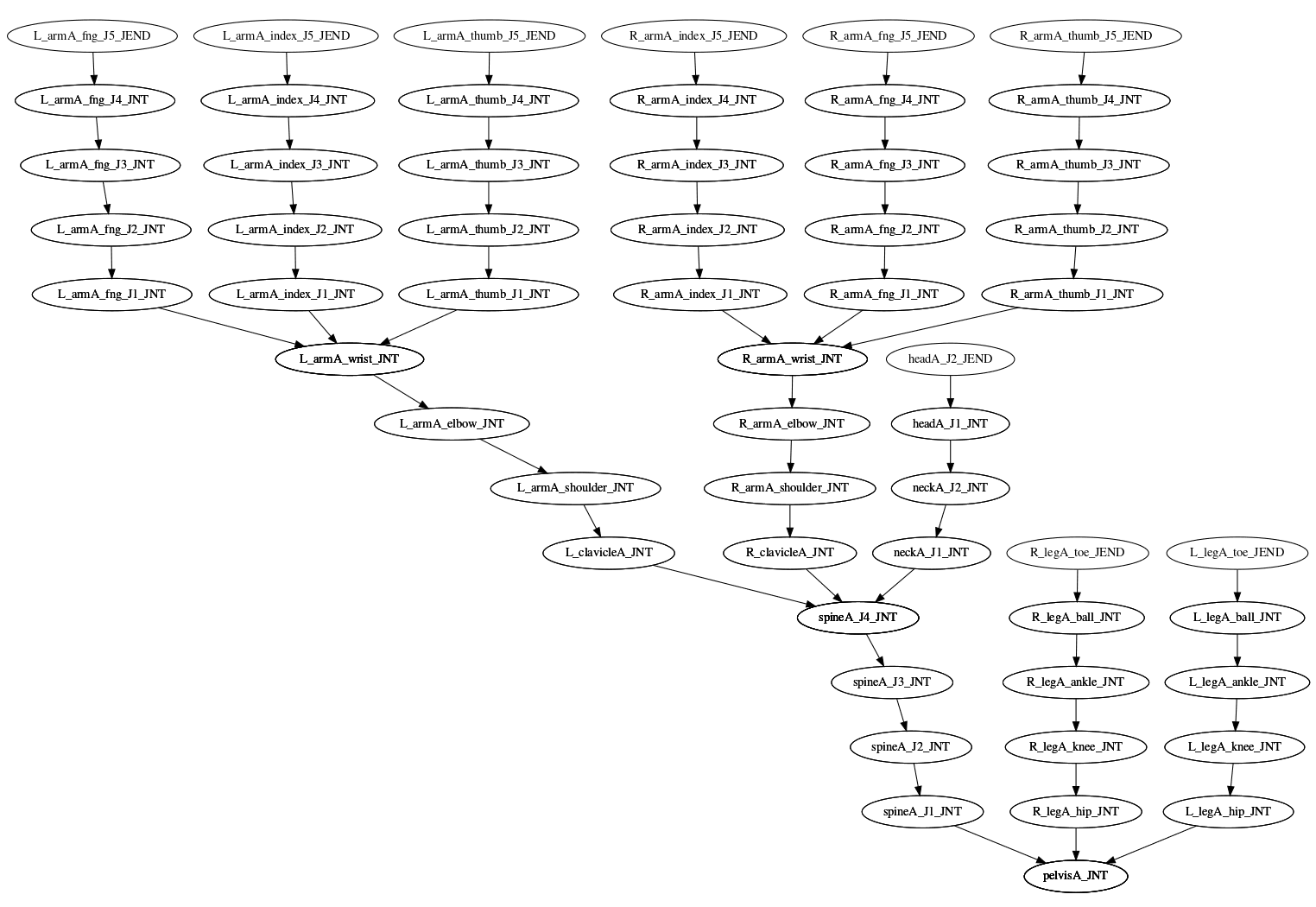
One area where we can gain a bit of graphics performance is by reducing the number of these nodes where they don’t have (much of) a visual impact. The fewer transforms we need to apply at runtime, the more time and memory we can dedicate to other tasks.
This is hugely important for FBX because it tends to result in far more nodes than are reasonable due to the flexibility of the format. Specifically, it allows the author to record not only 'translate', 'rotate', and 'scale' transforms at each node over time (which are the raw controls that animators tend to work with), but also 'pre', 'post', 'pivot', and 'offset' forms of these (which aren’t always directly exposed).
The full transform sequence required amounts to the following:
Note that there are terms between \(r\), \(s\), and \(t\). It may be possible to remove the pre, post, and offset transforms, but only if they are an identity transform. Otherwise, this doubles your node count. The \(r\), \(s\), and \(t\) terms can only be removed if no animation curve references them.
We were easily reaching over three hundred nodes on our character models. A great deal of these nodes are unnecessary.
Using libassimp
libassimp is definitely capable of representing these complex transforms. It stores transforms like \(r_\mathrm{pre}\) as virtual nodes within the tree; updating their names with suffixes like $AssimpFbx$_PreRotation.
Collapsing unnecessary nodes is a fairly straightforward operation. We can walk the node tree, check if each node has been referenced, and if not we fold it into the parent node. libassimp can be instructed to do this with the option AI_CONFIG_IMPORT_FBX_PRESERVE_PIVOTS=false. However experiments with this option showed a number of cases where transforms were lost or applied incorrectly.
Importantly, this approach only works if:
-
You consider every related file together. Just because the contents of 'model.fbx' don’t reference the 'elbow' node doesn’t mean that '[email protected]' won’t.
-
Every file is loaded with exactly the same options. The exact counts and values of many structures must match between files. If one node is missing then every subsequent transform may be incorrect.
I need a way to extract the data from all related files, construct a list of all referenced nodes, analyse all the associated transforms to check if any can be collapsed, and then perform the modifications. If we’re even slightly off in the data matching we end up with missing nodes, and animations with misplaced limbs.
libassimp does store the required values in the virtual nodes, but accessing the data proved fragile and it was not 100% reliable when it removed unnecessary nodes. It also failed to create identical node hierarchies between files that were based on the same skeleton; there were inconsistencies when just animation curves, or just geometry, were present. This led to situations where limbs further from the root node were progressively more distorted or detached.
libassimp FBX importI could have modified the library to include the necessary functionality, but it would have been an involved process and I’ve had ongoing issues maintaining libassimp and it’s dependencies. [2]
libcruft-mesh
So I expanded our mesh processing library to include FBX loading support over the last couple of months. This was simplified somewhat because we do not need to support all the functionality FBX provides. Only the subset which Maya and Blender exercise.
The extensions to libcruft-mesh give direct access to each of the node’s internal transforms so a more complete decision can be made about which nodes are required.
And we take great pains to ensure that every file is loaded without a loss of information, regardless of whether the data appears to be used, so that we increase the accuracy of cross-file comparisons.
As a side effect this is prompting me to more closely integrate mesh processing algorithsm I’ve developed in libcruft-mesh, such as auto-LOD generation and cache optimising index reordering.
Documentation
Coming back from holidays, reading some recently committed code, and feedback from James' perusal of the (woefully out of date) user manual during testing I’ve realised I need to work on all forms of documentation this year.
So part of this week was spent adding some documentation to libcruft-mesh, updating the system manual (so that I don’t forget how all the above systems work), and reinitialising this blog.
I’ve thrown together a fairly minimal install of the nikola static site generator. It seems to do exactly what it says on the tin, and largely stay out of my way. I’m pretty happy with it so far.
TODO
There’s still work to be done automatically linking 'model' and 'animation' files within our build system but the functionality is there if you hold the system’s hand. Finishing the implicit linking and configuration driven linking of '.fbx' files will be a job for the coming week.
pkg-config to identify library paths and flags for our dependencies. But many packages fail to pass at least one of the flags that the toolchain requires for cross-compilation; if you’re using CMake you need to be using IMPORTED_TARGET with pkg_check_modules. Header and library paths are particularly problematic as they can lead to the inadvertent use of libraries that are part of my local system.
zlib doesn’t even maintain a consistent library name across target systems; Windows is zlib1.dll and Linux is libz.so.1.